Java Compile Process
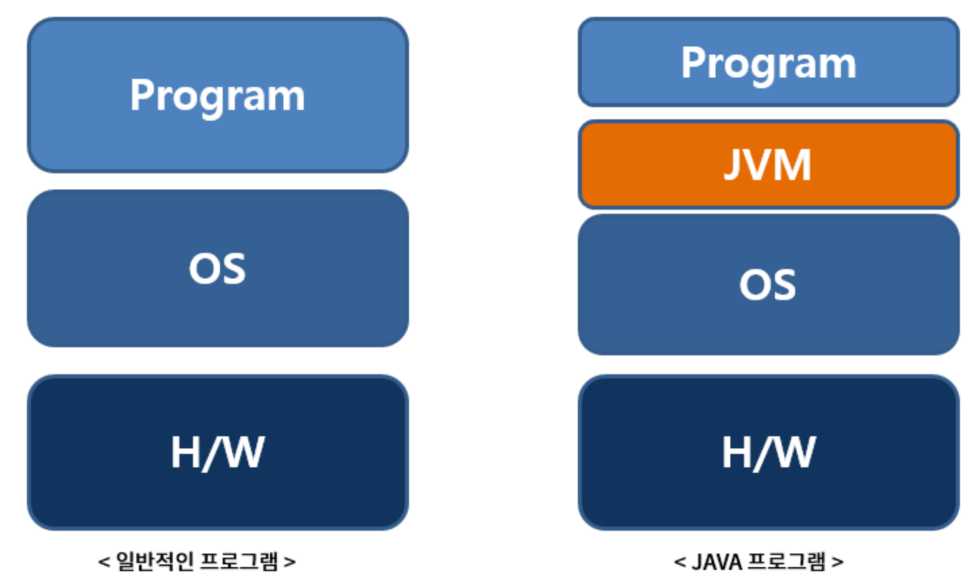
자바는 OS 에 독립적인 특징 (WORA: Write Once Run Anywhere) 을 가지고 있다. 어떻게 OS 에 독립적인 특징을 가질 수 있을까? 이는 JVM 때문이라고 할 수 있다.
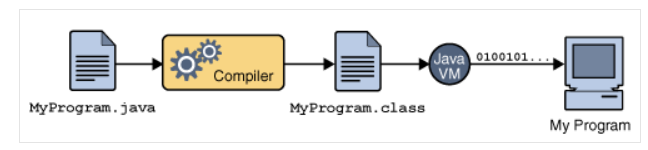
자바는 Compiler ( javac.exe ) 에 의해 '.java' 파일을 java bytecode 로 변환해 '.class' 파일을 만든다. '.class' 파일에 쓰여진 java bytecode 는 java JVM( Java Virtual Machine ) 에 의해(정확히는 JIT Java-In-Time compilation 또는 동적번역 Dynamic-Translation 에 의해) binary 파일로 변환되고 컴퓨터가 이해하는 저수준의 언어가 되어 실행되게 된다.
즉, 자바 Compiler(javac.exe) 에 의해 '.java' 파일은 JVM(정확히는 JRE Java-Runtime-Environment 에 의해) 이 이해하는 '.class' 파일인 java bytecode 가 되고, JIT comile 을 통해 OS 가 이해하는 기계어로 변환된다.
Java 코드를 실행하려면 두 번 컴파일해야 한다.
- Java(또는 Kotlin) 프로그램은 바이트코드로 컴파일해야 한다. (Javac.exe/Kotlin의 경우 kotlinc-jvm)
- 바이트코드가 실행되면 기계어로 변환해야 한다. (JIT compile)

Java와 Kotlin 코드는 프로그램 실행 시점 전인 컴파일 타임에 바이트 코드로 변환이 모두 완료되고, 실행 시점 전에 컴파일한다해서 정적 컴파일이라 한다.
JVM에서 바이트 코드들을 기계어로 번역하는 컴파일러가 바로 JIT 컴파일러이고, RunTime 시점에 컴파일한다해서 동적 컴파일(인터프리트 언어)이라 한다.
JVM의 JIT 컴파일러 내부에는 2가지 컴파일러인 C1컴파일러와 C2컴파일러가 있다. C1 컴파일러는 런타임에 바이트 코드를 기계어로 변환하는 과정만을 수행하며 C2 컴파일러는 런타임에 바이트 코드를 기계어로 변환한다음 캐시에 저장하는 과정을 수행한다.
이러한 캐시기능덕에, 사용할 때마다 바이트 코드 대신 고급 언어 에서 코드를 컴파일하는 다른 "인터프리터 언어"보다 빠르다 .
JIT 에 좀 더 살펴보자.
JIT 는 Java2라고 불리던 Java1.2 부터 추가되었다. Just-In-Time 의 약자인 JIT 는 쉽게말해 '동적 변환' 이라고 보면 된다. 이러한 JIT 를 만든 이유는 프로그램 실행을 보다 빠르게 하기 위해서다. 명칭이 컴파일러이지만, 실행시에 적용되는 기술이다. 역사적으로, 컴퓨터 프로그램을 실행하는 방식은 두 가지로 나눌 수 있다. 하나는 인터프리트(Interpret) 방식이며, 다른 하나는 정적(Static) 컴파일 방식이다. 인터프리터 방식은 실행시마다 컴퓨터 언어로 변환하기에 느릴 수 밖에 없다. 정적 컴파일은 실행하기 전 컴퓨터 언어로 변환하기에 변환 작업은 딱 한번만 수행하면 된다. JIT 는 이 두 가지 방식을 혼합한 것이다. 변환 작업은 인터프리터에 의해서 지속적으로 수행되지만, 위에서 설명 했듯이 필요한 코드의 정보는 캐시에 담아두었다가(메모리에 올려둠) 재사용하게 된다. JIT를 사용하면 반복적으로 수행되는 코드는 매우 빠른 성능을 보인다는 장점이 있다. 반대로 처음에 시작할 때에는 변환 단계를 거쳐야 하므로 느릴 수 있지만, 최근 JDK 성능 및 CPU 성능이 많이 좋아져 단점도 많이 개선되었다.
Compile 이란 과정을 살펴보자.
컴파일러는 프로그래밍 언어의 소스 코드를 특정 기계 전용 기계 코드로 변환한다.
컴파일러가 하는 행동이 컴파일인데, 컴파일은 다음의 과정을 거친다.
- 어휘 분석 Lexical analysis
- 구문 분석 Syntax analysis
- 의미 분석 Semantic analysis
- 중간코드 생성 Intermediate code generation
- 최적화 Optimization
- 코드생성 Code generation
- 기타 : Symbol Table , Error Handler
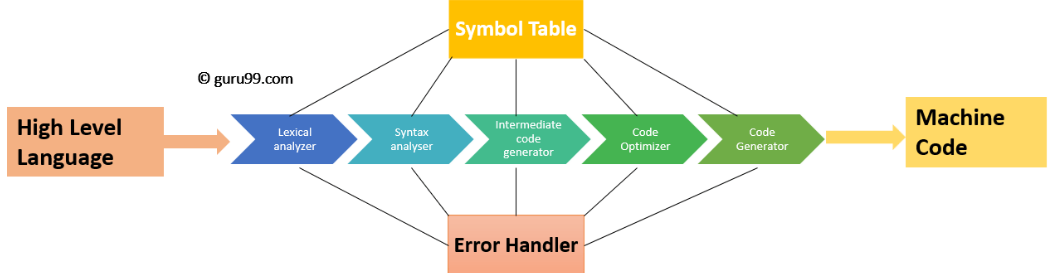
즉, 컴파일은 Token으로 분할하고, AST 를 만들고, 소스 코드를 최적화하여 소스 코드를 변환하는 과정이라 할 수 있다.
- 어휘 분석 Lexical analysis
Lexical analysis 는 구문분석을 하기위해 의미가 있는 문자열을 token-name , token-value 형태의 한 쌍으로 묶는 Token 으로 만들어 낸다. Lexical Analyzer는 이러한 토큰을 생성하는 동안 공백과 주석을 건너뛰고, 오류가 있는 경우 Lexical Analyzer 는 해당 오류를 소스 파일 및 줄 번호와 연관시킨다.
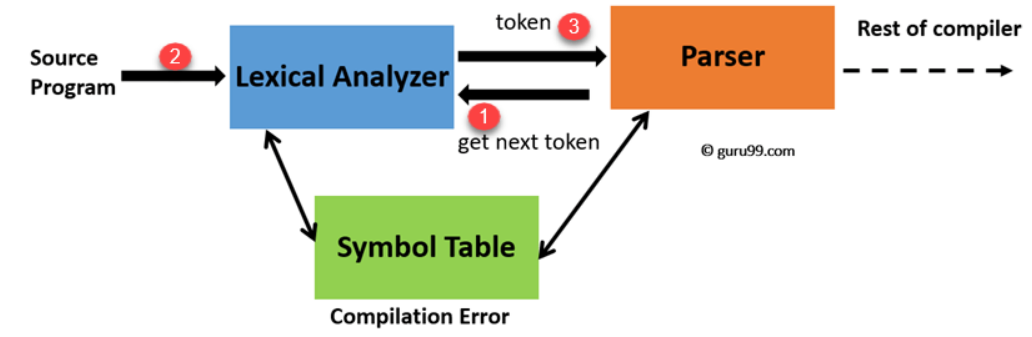
- "다음 토큰 가져오기"는 구문 분석기(Syntax analyzer) 에서 어휘 분석기(Lexical Analyzer) 로 보내는 명령이다.
- 이 명령을 수신하면 어휘 분석기 Lexical Analyzer 는 다음 토큰을 찾을 때까지 입력을 스캔한다.
- 토큰을 Parser에 반환한다.
- 구문 분석 Syntax analysis
전 단계인 Lexical Analysis 단계에서 생성된 토큰 시퀀스를 사용한다. 토큰은 프로그램의 논리적 구조를 나타내는 트리 인 추상 구문 트리 (AST Abstract-Syntax-Tree) 라는 구조를 만드는 데 사용된다 .
Systax analysis 단계의 Parsing 을 통해 소스 코드의 문법 구조와 구문 정확성을 확인한다. 이때, 구문 오류(syntax errors)는 컴파일 오류(compilation errors)를 초래하고 컴파일러는 개발자에게 이를 알린다.
즉, 이 단계의 주요 목표는 프로그래머가 작성한 소스 코드가 올바른지 확인하는 것이다.
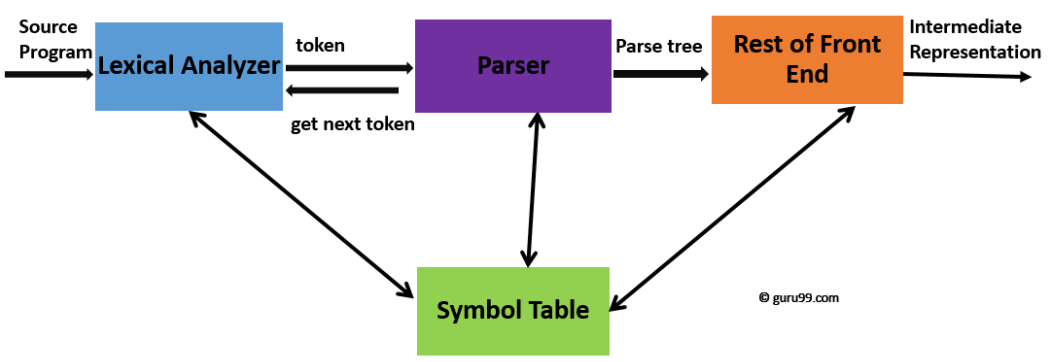

추가적으로 추상 구문 트리 (AST Abstract-Syntax-Tree) 는 다음 단계 의미 분석(Semantic analysis) 에서 코드가 일관성이있고 적절한지 판단하는데 사용된다.
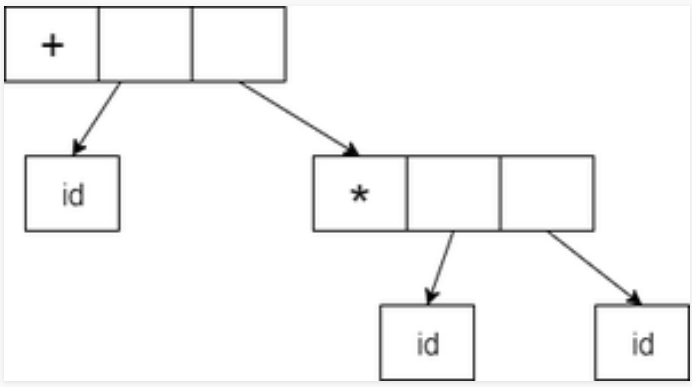
AST 는 다음과 같은 구조로 이루어졌다고 보면된다. (아래 사진 출처)
 |
 |
- 의미 분석 Semantic analysis
Semantic analysis 단계에서 컴파일러는 추상 구문 트리를 사용하여 의미 오류를 감지한다 . 예를 들면 다음과 같다.
- 변수에 잘못된 유형 할당
- 같은 범위에서 같은 이름의 변수 선언
- 선언되지 않은 변수 사용
- 언어의 키워드를 변수 이름으로 사용
Semantic analysis 단계에서 유형 불일치의 경우 유형 수정 규칙이 있다면 다음과 같은 변환을 하기도한다.
float x = 20.2;
float y = x*30;위의 코드에서 Semantic Analyzer는 곱하기 전에 정수 30 을 부동 소수점 30.0으로 유형 변환한다.
- 중간 코드 생성 Intermediate code generation
전 단계인 Semantic analysis 가 컴파일러를 통해 끝나면 시스템에 대한 중간 코드를 생성한다. 중간 코드는 기계에 독립적이여서, 특정 시스템에 대해 고유한 컴파일러가 필요하지 않다 .
중간 코드는 고급 언어와 기계 언어 사이에 있다. 때문에 중간 코드는 기계 코드로 쉽게 변환할 수 있는 방식으로 생성되어야 한다.
중간 코드 생성은 다음과 같은 형태로 변환된다고 보면 된다
total = count + rate * 5결과
t1 := int_to_float(5)
t2 := rate * t1
t3 := count + t2
total := t3
- 최적화 Optimization
최적화 Optimization 단계에서 컴파일러는 다양한 방법을 사용하여 코드의 효율성을 높인다. 이 단계의 주요 목표는 더 빠르게 실행되고 더 적은 공간을 차지하는 코드를 생성하도록 중간 코드를 개선하는 것이다.
다음과 같은 작업이 이루어진다고 보면 된다.
a = intofloat(10)
b = c * a
d = e + b
f = d결과
b =c * 10.0
f = e+b
( 참고할 만한 글 : 함수 인라인 )
- 코드생성 Code generation
마지막으로 컴파일러는 최적화된 중간 코드를 대상 기계 전용 기계어로 변환한다. 모든 메모리 위치와 레지스터도 이 단계에서 선택 및 할당된다.
예시로 다음과 같은 레지스터 할당이 될 수 있다.
a = b + 60.0MOVF a, R1
MULF #60.0, R2
ADDF R1, R2
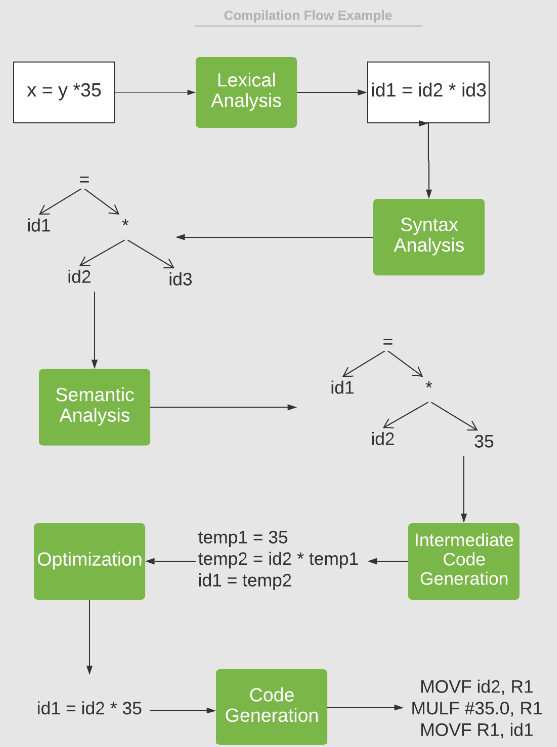
Symbol Table 과 Error Handler 는 모든 단계와 상호 작용하고 그에 따라 Symbol Table 이 업데이트된다.
- Symbol Table
Symbol Table 은 이름에 대한 범위 및 바인딩 정보, 변수 및 함수 이름, 클래스, 물건 등 변수의 의미를 추적하기 위해 컴파일러에 의해 생성되고 유지되는 중요한 데이터 구조이다.
하나의 예시로 각 단계별로 다음과 같이 상호작용 한다.
1. 어휘 분석: 예를 들어 토큰에 대한 항목과 같은 새 테이블 항목을 Symbol Table에 생성한다.
2. 구문 분석: 속성 유형, 범위, 차원, 참조 라인, 사용 등에 대한 정보를 테이블에 추가한다.
3. 의미 분석: Symbol Table에서 사용 가능한 정보를 사용하여 의미를 확인한다. 즉, 표현식과 할당이 의미적으로 올바른지 확인하고(유형 확인) 그에 따라 업데이트한다.
4. 중간 코드 생성 : 런타임이 얼마만큼, 어떤 종류가 할당되어 있는지 알기 위한 Symbol Table을 참조하고, Symbol Table은임시 변수 정보를 추가하는 데 도움이 된다.
5. 최적화: 기계 종속 최적화를 위해 Symbol Table에 있는 정보를 사용한다.
6. 코드 생성: Symbol Table에 있는 식별자의 주소 정보를 이용하여 코드를 생성한다.
( 참고할 만한 글 : Symbol Table )
- Error Handler
Compile 과정에서의 일어나는 Error 는 다음과 같은 예시를 들 수 있다.
1. 어휘 분석: 철자가 잘못된 토큰 ( 식별자 , 키워드 또는 연산자의 철자 오류가 포함 )
2. 구문 분석: 누락된 세미콜론 또는 불균형 괄호
3. 의미 분석: 연산자와 피연산자 간의 호환되지 않는 값 할당 또는 유형 불일치
4. 코드 생성: 연산자에 대해 일치하지 않는 피연산자
5. 최적화: 명령문에 도달할 수 없는 경우코드
6. 코드생성기: 메모리가 가득 차거나 적절한 레지스터가 할당되지 않은 경우
7. 기호 테이블: 선언된 여러 식별자의 오류
( 참고할 만한 글 : Error Handler 1 , Error Handler 2 )
참고 블로그1 , 참고 블로그2 , 참고 블로그3 , 참고 블로그4 , 참고 블로그5 , 참고 블로그6 , 참고 블로그7 , 참고 블로그8 , 참고 블로그9 , 참고 블로그10